Distributed Systems
➤ Explain the term “distributed systems”, contrasting it from “distributed computing” .
Distributed System is
A distributed system is a network that consists of autonomous computers that are connected using a distribution middleware. They help in sharing different resources and capabilities to provide users with a single and integrated coherent network.
The key features of a distributed system are:
- Components in the system are concurrent. A distributed system allows resource sharing, including software by systems connected to the network at the same time.
- There can be multiple components, but they will generally be autonomous in nature.
- A global clock is not required in a distributed system. The systems can be spread across different geographies.
- Compared to other network models, there is greater fault tolerance in a distributed model.
- Price/performance ratio is much better.
Distributed Computing is
The idea of distributing resources within a computer network is not new. This first started with the use of data entry terminals on mainframe computers, then moved into minicomputers and is now possible in personal computers and client-server architecture with more tiers.
A distributed computing architecture consists of a number of client machines with very lightweight software agents installed with one or more dedicated distributed computing management servers. The agents running on the client machines usually detect when the machine is idle and send a notification to the management server that the machine is not in use and available for a processing job. The agents then requests an application package. When the client machine receives this application package from the management server to process, it runs the application software when it has free CPU cycles and sends the result back to the management server. When the user returns and requires the resources again, the management server returns the resources was using to perform different tasks in the user's absence.

➤Compare and contrast the standalone systems with distributed systems, providing examples
for advantageous use of both.
Standalone System,
A standalone operating system is complete and works on a notebook or desktop computer. Standalone systems include DOS, Mac OS, Unix, Linux and OS/2 Warp Client. Windows standalones include Windows 3.x, Windows 95, Windows NT Workstation, Windows 98, Windows ME, Windows 2000 Professional and Windows XP Home and Professional editions.
There are also network operating systems that support a network. A network is a group of computers and/or devices connected via communication media through cables, modems and telephone lines. Network operating systems include Net-Ware, Unix, Linux, Solaris and OS/2 Warp Server for E-business. Windows network systems include Windows 2000 Server, Windows NT server and Windows.NET Serve
Advantages,
- Computer is damage control.
- Simplicity.
- more convenient.
Advantages of Distributed Systems,
1.Speed and Content Distribution
Distributed systems can also be faster than single-computer systems. One of the advantages of a distributed database is that queries can be routed to a server with a particular user's information, rather than all requests having to go to a single machine that can be overloaded.
2.Scaling and Parallelism
Once distributed systems are set up to distribute data among the servers involved, they can also be easily scalable. If they're well designed, it can be as simple as adding some new hardware and telling the network to add it to the distributed system.
Distributed systems can also be designed for parallelism. This is common in mathematical operations for things like weather modeling and scientific computing, where multiple powerful processors can divide up independent parts of complex simulations and get the answer faster than they would running them in series.
➤Discuss the elements of distributed systems.
1. Transparency
Transparency refers to hiding details from a user. The following types of transparency are desirable.
- Structure transparency: Multiple file servers are used to provide better performance, scalability, and reliability. The multiplicity of file servers should be transparent to the client of a distributed file system. Clients should not know the number or locations of file servers or the storage devices instead it should look like a conventional file system offered by a centralized, time sharing operating system.
- Access transparency: Local and remote files should be accessible in the same way. The file system should automatically locate an accessed file and transport it to the client’s site.
- Naming transparency: The name of the file should not reveal the location of the file. The name of the file must not be changed while moving from one node to another.
- Replication transparency: The existence of multiple copies and their locations should be hidden from the clients where files are replicated on multiple nodes.
2. User mobility
The user should not be forced to work on a specific node but should have the flexibility to work on different nodes at different times. This can be achieved by automatically bringing the users environment to the node where the user logs in.
3. Performance
Performance is measured as the average amount of time needed to satisfy client requests, which includes CPU time plus the time for accessing secondary storage along with network access time. Explicit file placement decisions should not be needed to increase the performance of a distributed file system.
4. Simplicity and ease of use
5. User interface to the file system be simple and number of commands should be as small as possible. A DFS should be able to support the whole range of applications.
6. Scalability
A good DFS should cope with an increase of nodes and not cause any disruption of service. Scalability also includes the system to withstand high service load, accommodate growth of users and integration of resources.
7. High availability
A distributed file system should continue to function even in partial failures such as a link failure, a node failure, or a storage device crash. Replicating files at multiple servers can help achieve availability.
8. High reliability
Probability of loss of stored data should be minimized. System should automatically generate backup copies of critical files in event of loss.
9. Data integrity
Concurrent access requests from multiple users who are competing to access the file must be properly synchronized by the use of some form of concurrency control mechanism. Atomic transactions can also be provided to users by a file system for data integrity.
10. Security
A distributed file system must secure data so that its users are confident of their privacy. File system should implement mechanisms to protect data that is stored within.
11. Heterogeneity
Distributed file system should allow various types of workstations to participate in sharing files via distributed file system. Integration of a new type of workstation or storage media should be designed by a DFS.
➤Identify examples for both browser-based and non-browser-based clients of distributed
systems
Lets focus on some of the common answers which are often received:
1. Web apps runs on a browser, client-server apps runs as .exe.
2. Web applications run on server, Client-Server apps run on client side.
3. Web application is thin client, client-server app is thick client.
6. Web apps are less secured, client-server apps are more secured.
1. To choose between Web or Client-Server technology:
2. Web applications run on server, Client-Server apps run on client side.
3. Web application is thin client, client-server app is thick client.
4. Web application does not need to be installed in client system, Client-server apps need to be installed in client system
5.Web apps need low maintenance, client-server apps need high maintenance6. Web apps are less secured, client-server apps are more secured.
Can we have only these words to compare a web application & a client server application? I agree in any interview we may not have hours to explain the differences but are we clear about our own conceptual knowledge? in most cases it has been found the basic concepts are not clear to IT professionals.
Lets dig little deeper into this............. (mostly bullet points, I know paras are annoying)
Any client requirement (except few rare ones) can be developed using either web or client-server technology, so where exactly are the differences? Lets ask ourselves the following questions:
- What are the factors which will decide which one to choose?
- Does the choice depends on business requirement?
- What are development & behavioral differences?
- What are maintenance differences?
Do we have answers of the above questions? lets find out.
When to choose Client-Server
- If the application need to be developed & implemented with very few target users.
- The budget does not permit to invest on a server hardware
- Need rapid development and deployment
- Need not be accessed beyond the local office boundary
- A rich user experience
- The application does not frequent version upgradation
- Lesser IT budget for both development & deployment
- No or limited availability of Internet connection
- When the application need to be developed for a specific platform
When to choose Web
- When there are numerous target users and need to be accessed from anywhere in world.
- The budget is not restriction to invest on a server hardware, in which the application can be hosted.
- Rapid development with limited UI functionalities, though modern IDEs provide rich UI look & feel
- The application need to be updated & versioned frequently
- High speed Internet connection available
- IT budget is not a constraint, as some security equipments are needed in prod environment
- When the application does not need to depend on users' platform. It only need to know the users' browser details.
- Where there is no dedicated admin team to deploy the updated application in each client system
- Application can be accessed over mobile.
2. Does the choice depends on business requirement:
As far as the functional requirements are concerned, it is not a major factor to decide between web or client-server technology.
But yes some non functional requirements (as mentioned above) stand as decision factors. Some of the specific UI need from client can also be a decision factor where a more complicated UI will suggest a client-server application.
3. What are development & behavioral differences:
The modern development does not differ much but behavior of a web & a client-server application differs lot.
Development of Web & Client-Server Application
Most of the major IDEs support development of both web & client-server applications. The IDEs load & configure themselves based on the type of the project selected.
Modern tools & technologies support event-driven approach for both web & client-server applications. This make the developer's life easier, but certainly there are differences:
Web app
- While developing web application we need to follow both server side coding (ASP/Java/Php) & client side coding (Vb script & Javascript). The client side coding eliminates postback of the application to server for small functionalities which can be performed on the browser memory itself. The javascript syntax will be same throughout the browsers.
- The developers need to know the event sequence to understand the page life cycle.
- While sharing data between multiple pages, the session memory need to be utilized. the session need to be managed by the server side coding whose syntax varies depending on the chosen IDE.
- Web development supports application memory of the web server through which data can be shared between multiple users.
- To make the UI compatible with all browsers, the CSS & common supportive features need to be utilized. This will make the web application independent of screen resolution.
- Few modern technologies like Ajax & JQuery need to be implemented to improve the performance of the application, through partial postback.
Client-Server app
- The developer need to know only the server side coding.
- The developers need to know the event sequence to understand the form life cycle.
- While sharing data between multiple forms the data need to be stored in public memory area, which can be accessed by all forms.
- The client server applications are not really independent of resolution, where some distortion happens depending on the screen resolution. Few modern technologies render the UI using some special technique to make it independent of resolution.
Behaviors of Client-Server Application:
- The app get compiled in form of .exe (assembly) file. The exe files when double clicked get executed which loads the compiled code (assembly) in the memory of the system where its been executed. Though latest technologies support just-in-time load of assembly in the memory, to avoid memory overload.
- Any UI activity are responded from the locally loaded assembly, hence are faster in response.
- All data (variables) are stored within the memory of the loaded assembly (.exe). These in memory variables can easily be shared & accessed between multiple forms.
- The in-memory variable data cannot be shared with other instances of the application in some other system.
- Any request to external resources (database, service)are communicated & managed by the loaded assembly (.exe).
- Any local references (.dll) are loaded within the memory space of the main assembly(.exe). This is termed as in-process communication and are always faster.
Behaviors of Web Application:
- A web application gets compiled in form of .dll (assembly) or just in form of some pages (html).
- The assembly(.dll) are loaded within the memory space of the web server. Separate memory are allocated for each user, so in case the app crashes for 1 user, it will not affect the other.
- The web application need to be hosted in a web server (IIS, Apache-Tomcat). Once hosted the application will have an Uniform Resource Locator(URL).
- The users need to access the application by typing the URL in a browser.
- The request from the browser will reach the web server, which will be parsed and the response will be sent back to the browser in form of HTML. The HTML will be rendered in the user's browser.
- Users' subsequent activity will be posted back to the web server and will pass through the same process sequence. This will have some performance degradation as it need to traverse between browser & web server & depends on Internet bandwidth on users' & server side.
- All data (variable) are stored within the memory space of the web server.
- Web server manages session for each user, and variable stored in session can be shared & accessed by pages between multiple postback.
- Any request to external resources (database, service) are managed by the web server & the memory space allocated to a particular user.
➤Discuss the characteristics of different types of Web-based systems, including the RiWAs
Functionality | Shows the existence of a set of functions and their specified properties. The functions satisfy stated or implied needs. |
| Reliability | That capability of software which maintains its level of performance under given conditions for a given period of time. |
| Usability | Attributes that determine the effort needed for use and the assessment of such use by a set of users. |
| Efficiency | The relationship between the level of performance of the software and the amount of resources used under stated conditions. |
| Maintainability | The effort needed to make specified modifications. |
| Portability | The ability of the software to be transformed from one environment to another. |
➤Explain different architectures for distributed systems, explaining special features of each
Layered Architecture
The layered architecture separates layers of components from each other, giving it a much more modular approach. A well known example for this is the OSI model that incorporates a layered architecture when interacting with each of the components. Each interaction is sequential where a layer will contact the adjacent layer and this process continues, until the request is been catered to. But in certain cases, the implementation can be made so that some layers will be skipped, which is called cross-layer coordination. Through cross-layer coordination, one can obtain better results due to performance increase.
The layers on the bottom provide a service to the layers on the top. The request flows from top to bottom, whereas the response is sent from bottom to top. The advantage of using this approach is that, the calls always follow a predefined path, and that each layer can be easily replaced or modified without affecting the entire architecture. The following image is the basic idea of a layered architecture style.

The image given below, represents the basic architecture style of a distributed system.
Object Based Architecture
This architecture style is based on loosely coupled arrangement of objects. This has no specific architecture like layers. Like in layers, this does not have a sequential set of steps that needs to be carried out for a given call. Each of the components are referred to as objects, where each object can interact with other objects through a given connector or interface. These are much more direct where all the different components can interact directly with other components through a direct method call.

As shown in the above image, communication between object happen as method invocations. These are generally called Remote Procedure Calls (RPC). Some popular examples are Java RMI, Web Services and REST API Calls. This has the following properties.
- This architecture style is less structured.
- component = object
- connector = RPC or RMI
When decoupling these processes in space, people wanted the components to be anonymous and replaceable. And the synchronization process needed to be asynchronous, which has led to Data Centered Architectures and Event Based Architectures.
Peer to Peer (P2P)
The general idea behind peer to peer is where there is no central control in a distributed system. The basic idea is that, each node can either be a client or a server at a given time. If the node is requesting something, it can be known as a client, and if some node is providing something, it can be known as a server. In general, each node is referred to as a Peer.

In this network, any new node has to first join the network. After joining in, they can either request a service or provide a service. The initiation phase of a node (Joining of a node), can vary according to implementation of a network. There are two ways in how a new node can get to know, what other nodes are providing.
- Centralized Lookup Server - The new node has to register with the centralized look up server an mention the services it will be providing, on the network. So, whenever you want to have a service, you simply have to contact the centralized look up server and it will direct you to the relevant service provider.
- Decentralized System - A node desiring for specific services must, broadcast and ask every other node in the network, so that whoever is providing the service will respond.
Client Server Architecture
The client server architecture has two major components. The client and the server. The Server is where all the processing, computing and data handling is happening, whereas the Client is where the user can access the services and resources given by the Server (Remote Server). The clients can make requests from the Server, and the Server will respond accordingly. Generally, there is only one server that handles the remote side. But to be on the safe side, we do use multiple servers will load balancing techniques.

As one common design feature, the Client Server architecture has a centralized security database. This database contains security details like credentials and access details. Users can't log in to a server, without the security credentials. So, it makes this architecture a bit more stable and secure than Peer to Peer. The stability comes where the security database can allow resource usage in a much more meaningful way. But on the other hand, the system might get low, as the server only can handle a limited amount of workload at a given time.
Advantages:
- Easier to Build and Maintain
- Better Security
- Stable
Disadvantages:
- Single point of failure
- Less scalable
Data Centered Architecture
As the title suggests, this architecture is based on a data center, where the primary communication happens via a central data repository. This common repository can be either active or passive. This is more like a producer consumer problem. The producers produce items to a common data store, and the consumers can request data from it. This common repository, could even be a simple database. But the idea is that, the communication between objects happening through this shared common storage. This supports different components (or objects) by providing a persistent storage space for those components (such as a MySQL database). All the information related to the nodes in the system are stored in this persistent storage. In event-based architectures, data is only sent and received by those components who have already subscribed.
Some popular examples are distributed file systems, producer consumer, and web based data services.

➤Compare and contrast the micro-service architecture from monolithic architecture
Microservices Architecture
The idea is to split your application into a set of smaller, interconnected services instead of building a single monolithic application. Each microservice is a small application that has its own hexagonal architecture consisting of business logic along with various adapters. Some microservices would expose a REST, RPC or message-based API and most services consume APIs provided by other services. Other microservices might implement a web UI.
The Microservice architecture pattern significantly impacts the relationship between the application and the database. Instead of sharing a single database schema with other services, each service has its own database schema. On the one hand, this approach is at odds with the idea of an enterprise-wide data model. Also, it often results in duplication of some data. However, having a database schema per service is essential if you want to benefit from microservices, because it ensures loose coupling. Each of the services has its own database. Moreover, a service can use a type of database that is best suited to its needs, the so-called polyglot persistence architecture.
Some APIs are also exposed to the mobile, desktop, web apps. The apps don’t, however, have direct access to the back-end services. Instead, communication is mediated by an intermediary known as an API Gateway. The API Gateway is responsible for tasks such as load balancing, caching, access control, API metering, and monitoring.
The Microservice architecture pattern corresponds to the Y-axis scaling of the Scale Cube model of scalability.
Monolithic Architecture
- This simple approach has a limitation in size and complexity.
- Application is too large and complex to fully understand and made changes fast and correctly.
- The size of the application can slow down the start-up time.
- You must redeploy the entire application on each update.
- Impact of a change is usually not very well understood which leads to do extensive manual testing.
- Continuous deployment is difficult.
- Monolithic applications can also be difficult to scale when different modules have conflicting resource requirements.
- Another problem with monolithic applications is reliability. Bug in any module (e.g. memory leak) can potentially bring down the entire process. Moreover, since all instances of the application are identical, that bug will impact the availability of the entire application.
- Monolithic applications has a barrier to adopting new technologies. Since changes in frameworks or languages will affect an entire application it is extremely expensive in both time and cost.
➤Explain the MVC style
Modal-View-Controller, originally referred to as 'Thing-Model-View-Controller' is a software architectural pattern introduced and implemented by Trygve Reenskaug while working at Xerox PARC in 1978. It was originally used as an architectural pattern for creating Graphical User Interfaces (GUIs), but it has also formed a fundamental part of how the internet works.
Trygve Reenskaug wrote a complete documentation about the MVC pattern that can be found here [^]. According to the documentation, "MVC was conceived as a general solution to the problem of users controlling a large and complex data set. The MVC pattern divides the entire application into three interconnected parts so that the data that is represented to the user is kept separate from how it is stored and represent internally." The three interconnected parts of the MVC pattern are:
- Model: Is the business layer of the application and is responsible for the data access. It contains the logic to access data that will eventually be displayed to the user. It is also responsible for business rules, validations and other things related to data access. However, it is unaware of how the data is being displayed to the user.
- View: Is the user interface of the application and is responsible for rendering the data from the Model to the user. It is unaware of how the data is retrieved and can render HTML, XML, JSON and other custom types.
- Controller: As the name suggests, it controls the entire application and is considered to be the most important part of the application. It is primarily responsible for handling the user inputs. It first determines what the user wants are and accordingly communicates with the Model and supplies data to the View to be displayed to the user. Without a controller, the Model doesn't know what data to get and the View.
- doesn't know what output to generate to the user.

➤Communication technologies
Middleware
● Software that manages and supports the different components of a distributed system. In essence, it sits in the middle of the system.
● Middleware is usually off-the-shelf rather than specially written software.
● Examples
• Transaction processing monitors;
• Data converters;
• Communication controllers
➤Discuss the need for very specific type of communication technologies/techniques for the
distributed/web-based systems.
To address the challenge described above, therefore, three levels of support for distributed computing were developed:
ad hoc network programming, structured communication, and middleware. Ad hoc network programming includes
interprocess communication (IPC) mechanisms, such as shared memory, pipes, and sockets, that allow distributed
components to connect and exchange information. These IPC mechanisms help address a key challenge of distributed
computing: enabling components from different address spaces to cooperate with one another.
Certain drawbacks arise, however, when developing distributed systems only using ad hoc network programming
support. For instance, using sockets directly within application code tightly couples this code to the socket API. Porting
this code to another IPC mechanism or redeploying components to different nodes in a network thus becomes a costly
manual programming effort. Even porting this code to another version of the same operating system can require code
changes if each platform has slightly different APIs for the IPC mechanisms [POSA2] [SH02]. Programming directly
to an IPC mechanism can also cause a paradigm mismatch, e.g., local communication uses object-oriented classes and
method invocations, whereas remote communication uses the function-oriented socket API and message passing.
The next level of support for distributed computing is structured communication, which overcomes limitations with ad
hoc network programming by not coupling application code to low-level IPC mechanisms, but instead offering higherlevel
communication mechanisms to distributed systems. Structured communication encapsulates machine-level
details, such as bits and bytes and binary reads and writes. Application developers are therefore presented with a
programming model that embodies types and a communication style closer to their application domain.
Historically significant examples of structured communication are remote procedure call (RPC) platforms, such as Sun
RPC and the Distributed Computing Environment (DCE). RPC platforms allow distributed applications to cooperate
with one another much like they would in a local environment: they invoke functions on each other, pass parameters
along with each invocation, and receive results from the functions they called. The RPC platform shields them from
details of specific IPC mechanisms and low-level operating system APIs. Another example of structured
communication is ACE [SH02] [SH03], which provides reusable C++ wrapper facades and frameworks that perform
common structured communication tasks across a range of OS platforms.
Despite its improvements over ad hoc network programming, structured communication does not fully resolve the
challenges described above. In particular, components in a distributed system that communicate via structured
communication are still aware of their peers’ remoteness—and sometimes even their location in the network. While
location awareness may suffice for certain types of distributed systems, such as statically configured embedded
systems whose component deployment rarely changes, structured communication does not fulfill the following the
properties needed for more complex distributed systems:
• Location-independence of components. Ideally, clients in a distributed system should communicate with collocated
or remote services using the same programming model. Providing this degree of location-independence requires the
separation of code that deals with remoting or location-specific details from client and service application code.
Even then, of course, distributed systems have failure modes that local systems do not have [WWWK96].
• Flexible component (re)deployment. The original deployment of an application’s services to network nodes could
become suboptimal as hardware is upgraded, new nodes are incorporated, and/or new requirements are added. A
redeployment of distributed system services may therefore be needed, ideally without breaking code and or shutting
down the entire system.
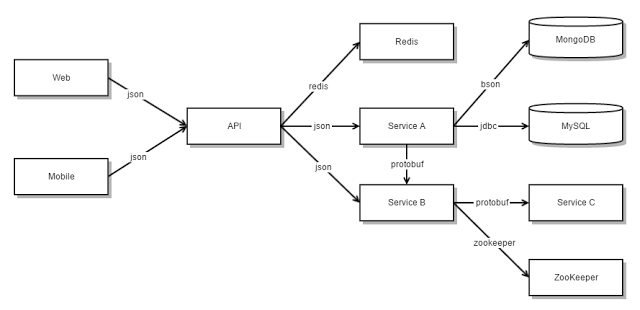
JSON is parsed into a ready-to-use JavaScript object.
➤Compare and contrast RPC with RMI
RPC,
Remote Procedure Call (RPC) is a protocol that one program can use to request a service from a program located in another computer on a network without having to understand the network's details. A procedure call is also sometimes known as a function call or a subroutine call.
RPC uses the client-server model. The requesting program is a client and the service providing program is the server. Like a regular or local procedure call, an RPC is a synchronous operation requiring the requesting program to be suspended until the results of the remote procedure are returned. However, the use of lightweight processes or threads that share the same address space allows multiple RPCs to be performed concurrently.
RPC message procedure
When program statements that use RPC framework are compiled into an executable program, a stub is included in the compiled code that acts as the representative of the remote procedure code. When the program is run and the procedure call is issued, the stub receives the request and forwards it to a client runtime program in the local computer.
The client runtime program has the knowledge of how to address the remote computer and server application and sends the message across the network that requests the remote procedure. Similarly, the server includes a runtime program and stub that interface with the remote procedure itself. Response-request protocols are returned the same way
RPC models and alternative methods for client-server communication
There are several RPC models and distributed computing implementations. A popular model and implementation is the Open Software Foundation's Distributed Computing Environment (DCE). The Institute of Electrical and Electronics Engineers defines RPC in its ISO Remote Procedure Call Specification, ISO/IEC CD 11578 N6561, ISO/IEC, November 1991.
RPC spans the transport layer and the application layer in the Open Systems Interconnection model of network communication. RPC makes it easier to develop an application that includes multiple programs distributed in a network.
RMI,
RMI (Remote Method Invocation) is a way that a programmer, using the Java programming language and development environment, can write object-oriented programming in which objects on different computers can interact in a distributed network. RMI is the Java version of what is generally known as a remote procedure call (RPC), but with the ability to pass one or more objects along with the request. The object can include information that will change the service that is performed in the remote computer. Sun Microsystems, the inventors of Java, calls this "moving behavior." For example, when a user at a remote computer fills out an expense account, the Java program interacting with the user could communicate, using RMI, with a Java program in another computer that always had the latest policy about expense reporting. In reply, that program would send back an object and associated method information that would enable the remote computer program to screen the user's expense account data in a way that was consistent with the latest policy. The user and the company both would save time by catching mistakes early. Whenever the company policy changed, it would require a change to a program in only one computer.
Sun calls its object parameter-passing mechanism object serialization. An RMI request is a request to invoke the method of a remote object. The request has the same syntax as a request to invoke an object method in the same (local) computer. In general, RMI is designed to preserve the object model and its advantages across a network.
➤Explain the need for CORBA, indicating it’s use in web-based systems
CORBA enables separate pieces of software written in different languages and running on different computers to work with each other like a single application or set of services. More specifically, CORBA is a mechanism in software for normalizing the method-call semantics between application objects residing either in the same address space (application) or remote address space (same host, or remote host on a network).
CORBA applications are composed of objects that combine data and functions that represent something in the real world. Each object has multiple instances, and each instance is associated with a particular client request. For example, a bank teller object has multiple instances, each of which is specific to an individual customer. Each object indicates all the services it provides, the input essential for each service and the output of a service, if any, in the form of a file in a language known as the Interface Definition Language (IDL). The client object that is seeking to access a specific operation on the object uses the IDL file to see the available services and marshal the arguments appropriately.
The CORBA specification dictates that there will be an object request broker (ORB) through which an application interacts with other objects. In practice, the application simply initializes the ORB, and accesses an internal object adapter, which maintains things like reference counting, object (and reference) instantiation policies, and object lifetime policies. The object adapter is used to register instances of the generated code classes. Generated code classes are the result of compiling the user IDL code, which translates the high-level interface definition into an OS- and language-specific class base to be applied by the user application. This step is necessary in order to enforce CORBA semantics and provide a clean user process for interfacing with the CORBA infrastructure.
➤XML and JSON
JSON is Like XML Because
- Both JSON and XML are "self describing" (human readable)
- Both JSON and XML are hierarchical (values within values)
- Both JSON and XML can be parsed and used by lots of programming languages
- Both JSON and XML can be fetched with an XMLHttpRequest
JSON is Unlike XML Because
- JSON doesn't use end tag
- JSON is shorter
- JSON is quicker to read and write
- JSON can use arrays
The biggest difference is:
XML has to be parsed with an XML parser. JSON can be parsed by a standard JavaScript function.
Why JSON is Better Than XML
XML is much more difficult to parse than JSON.JSON is parsed into a ready-to-use JavaScript object.
For AJAX applications, JSON is faster and easier than XML:
Using XML
- Fetch an XML document
- Use the XML DOM to loop through the document
- Extract values and store in variables
Using JSON
- Fetch a JSON string
- JSON.Parse the JSON string
➦References

Comments
Post a Comment